On January 3rd, 2026, someone turned $32,000 into $436,000 in a single day on Polymarket. They bet on Venezuelan president Nicolás Maduro's capture, one hour before the U.S. government announced it. The account, "Burdensome-Mix," was created less than a week prior. It only ever bet on Venezuela-related markets. After the win, the username changed to a random string of characters. The DOJ and CFTC opened a joint investigation.
Around the same time, another trader made over $1 million correctly predicting 22 out of 23 Google Year in Search results. The same account had also predicted the exact release date of Gemini 3.0.
Prediction markets move billions of dollars. Traditional stock markets have the SEC, FINRA, and an entire surveillance apparatus watching every trade. Prediction markets have nothing. No surveillance infrastructure. No detection systems. No accountability.
So I built one.
Why I Built This (And Why It Almost Didn't Happen)
Two weeks before Argus existed, I was building something completely different. I was 15 days into a ColorStack Winter Break Hackathon project, a different idea entirely, when the Maduro story broke across crypto Twitter. I read the on-chain analysis. A fresh wallet, a single massive bet, perfect timing, a name change to cover tracks. It was textbook insider trading, and nobody caught it until after the money was gone.
I couldn't stop thinking about it. Prediction markets are supposed to be this pure information mechanism, prices reflecting what the crowd actually believes. But if insiders can trade on privileged information with zero risk of detection, the prices aren't reflecting belief. They're reflecting corruption. And nobody was building anything to stop it.
The next morning I scrapped my hackathon project and started over. Argus went from concept to working system in under two weeks, built solo, running on caffeine and the conviction that this problem mattered more than whatever I'd been building before.
This is the technical breakdown of how it works.
Architecture Overview
Argus isn't a chatbot. It's not a dashboard with an AI button. It's an autonomous agent. You give it tools, point it at data, and it investigates on its own.
Stack:
- Frontend: Next.js 15, React 19, Tailwind CSS
- Backend: Convex (serverless database + real-time subscriptions + cron jobs)
- AI: Claude Opus 4.5 via AWS Bedrock
- Data sources: Polymarket Data API, Polymarket Gamma API, The Graph subgraph (on-chain data)
The data flow:
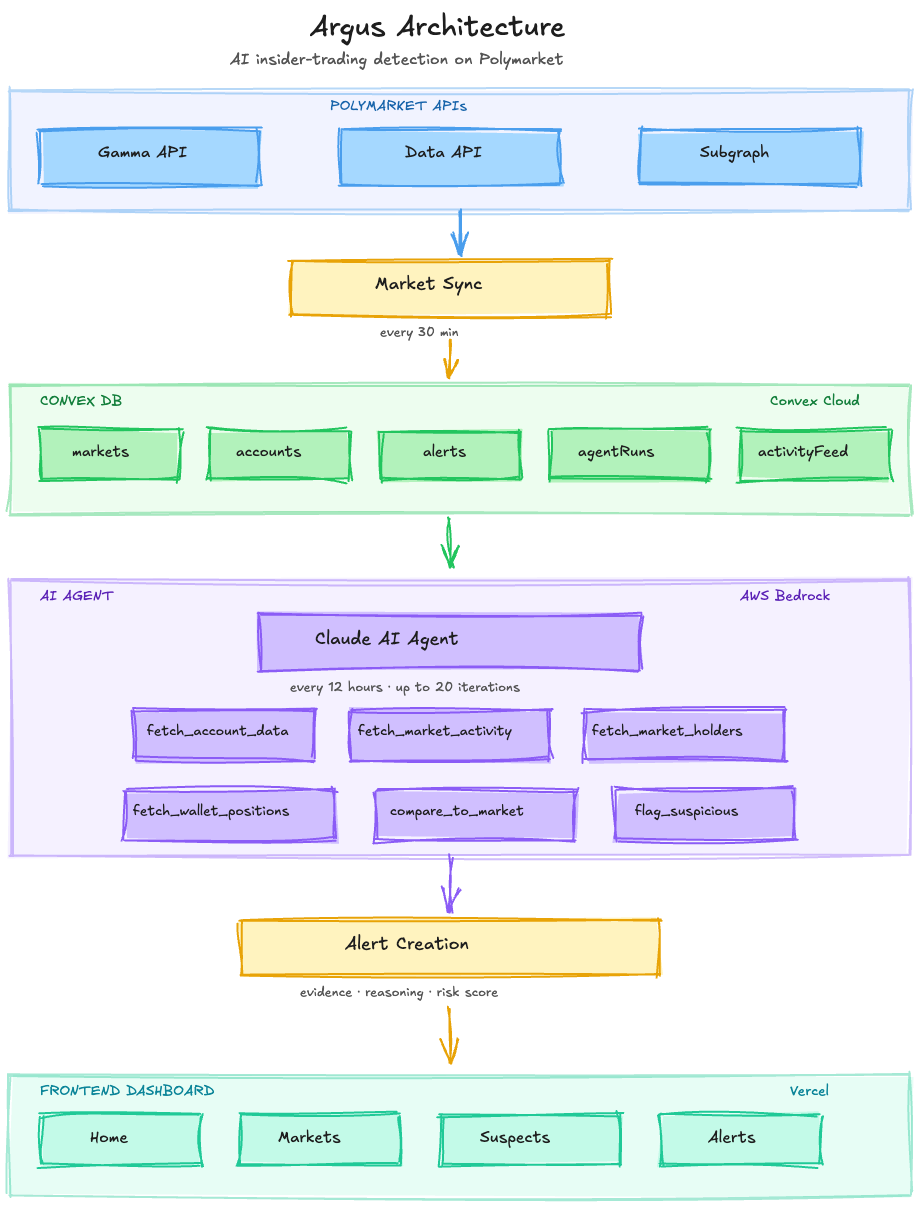
Cron jobs orchestrate the pipeline. Market data syncs regularly from the Gamma API, filtered by category tags and keywords. Multiple times a day, the agent wakes up, receives a list of active markets, and runs its investigation autonomously. A separate job cleans up the activity feed. The system runs 24/7 with no human in the loop.
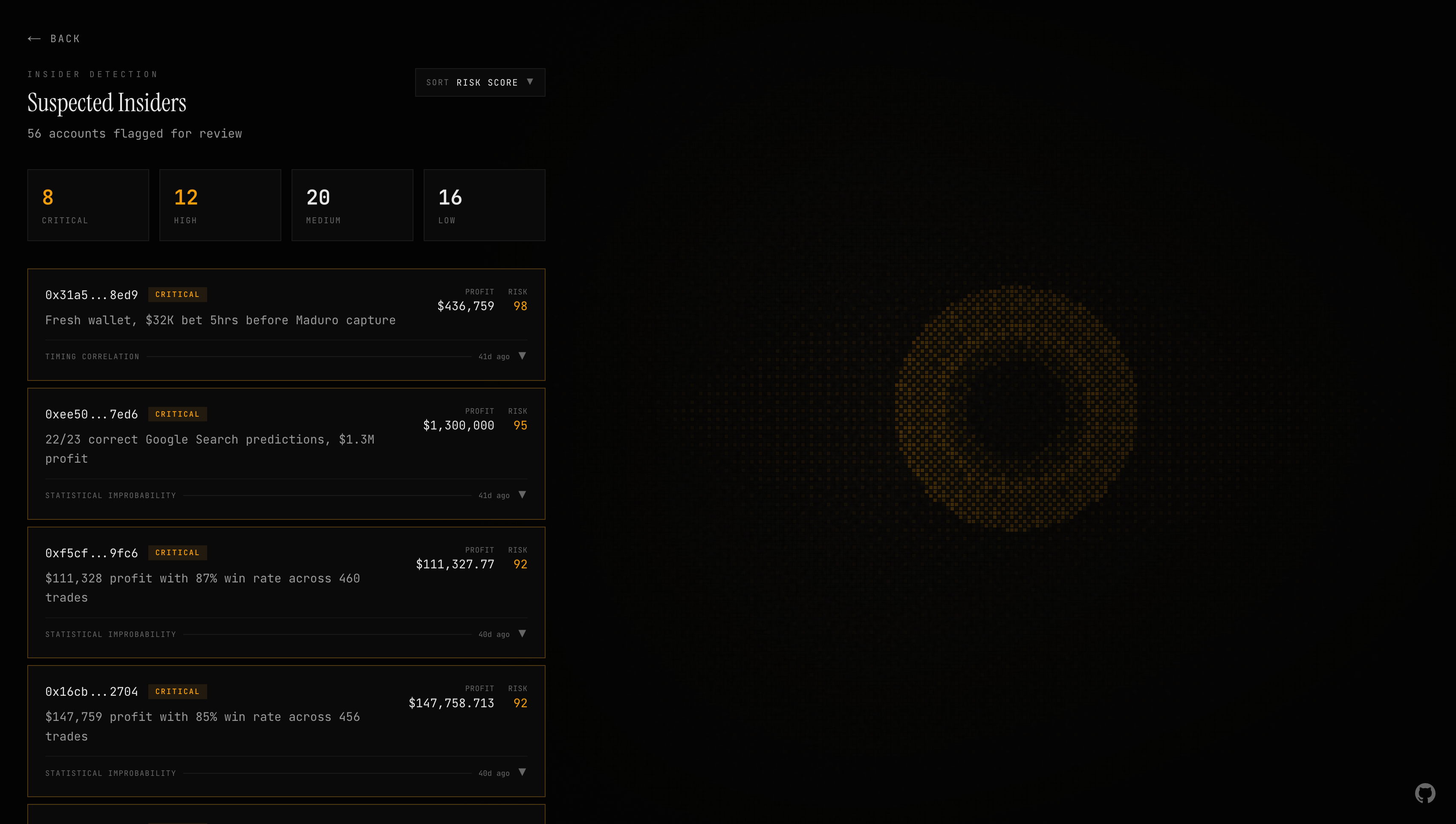
The AI Agent
This is the core of Argus. A fully autonomous agentic loop that decides its own investigation strategy. Not a prompt-response system, but an agent that reasons through each case the way a financial crimes analyst would.
How the Loop Works
The agent runs on Claude via the AWS Bedrock Converse API. The loop:
- Initialize: Receives a list of market IDs to investigate plus a system prompt teaching financial crimes investigation methodology, including real case studies like the Maduro insider and the AlphaRaccoon Google predictions, with detailed signal breakdowns.
- Iterate (up to 50 turns): Send conversation history + tool definitions to Claude, extract tool calls, execute them in parallel via
Promise.all, append results, repeat. - Return: Success/failure, iteration count, tool call log, token usage.
The agent decides which tools to call and in what order. It reasons through each investigation step, builds context incrementally, and makes judgment calls about what warrants flagging. No hardcoded decision trees. No if-else chains. The agent reads the data, thinks about what it means, and decides what to do next.
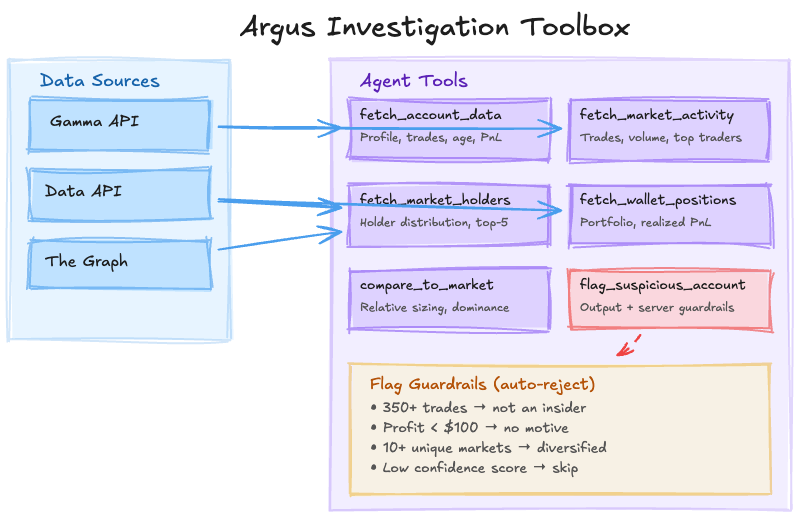
The Toolbox
The agent has six tools. Each wraps specific API calls and returns structured data for the agent to reason over:
| Tool | What it does |
|---|---|
fetch_account_data | Deep profile from 3 APIs: trade history, on-chain account age, name change detection (regex for hex strings/UUIDs), win rate, PnL breakdown, trades near resolution times |
fetch_market_activity | Market-level context: trades, volume, unique traders, large trade count (>$5K), average trade size, top 10 traders |
fetch_market_holders | Holder distribution, top-5 concentration ratio, largest holder percentage |
fetch_wallet_positions | Full portfolio across all markets with realized/unrealized PnL and largest position |
compare_to_market | Relative analysis: bet size vs. average, dominance %, volume percentile, whale/dominant/top-trader flags |
flag_suspicious_account | Output tool with server-side guardrails: rejects flags on accounts with 350+ trades, profit under $100, 10+ unique markets, or low confidence scores |
The tools give the agent everything it needs to build a complete picture of any trader: who they are, what they've done, how they compare to the market, and whether their behavior pattern matches known insider trading cases.
What the Agent Looks For
The agent's system prompt teaches it to evaluate traders across several signal dimensions. These aren't hardcoded rules. They're the investigation framework the agent uses to reason about each case:
| Signal | What it tells the agent |
|---|---|
| Wallet age | Insiders create fresh accounts to avoid linking trades to their identity |
| Trade count | Insiders bet and disappear. Experienced traders have hundreds of trades across many markets. |
| Market concentration | Normal traders diversify. Insiders go all-in on the one market where they have information. |
| Win rate vs. trade count | A 95% win rate over 5 trades is suspicious. A 60% win rate over 500 trades is a skilled trader. |
| Relative bet size | A trade that's 10x the market average stands out. The agent compares every trade to its market context. |
| Market dominance | Controlling 70% of a market is a very different signal than holding 0.1%. |
| Profit | Insiders don't lose money. Low or negative profit is an instant disqualifier. |
The critical insight built into the agent's reasoning: relative metrics matter more than absolute ones. A $5,000 bet means completely different things depending on the market. In a $10,000 market, that's 50% dominance, extremely suspicious. In a $10 million market, it's a rounding error. The compare_to_market tool builds this context automatically, giving the agent average trade sizes, total volume, holder counts, and a wallet dominance map for every market it investigates.
No single signal triggers a flag. The agent is taught that it needs multiple converging signals on the same account. A fresh account alone isn't suspicious. A high win rate alone isn't suspicious. But a fresh account + high win rate + single market focus + large position relative to market size? That's a pattern worth flagging.
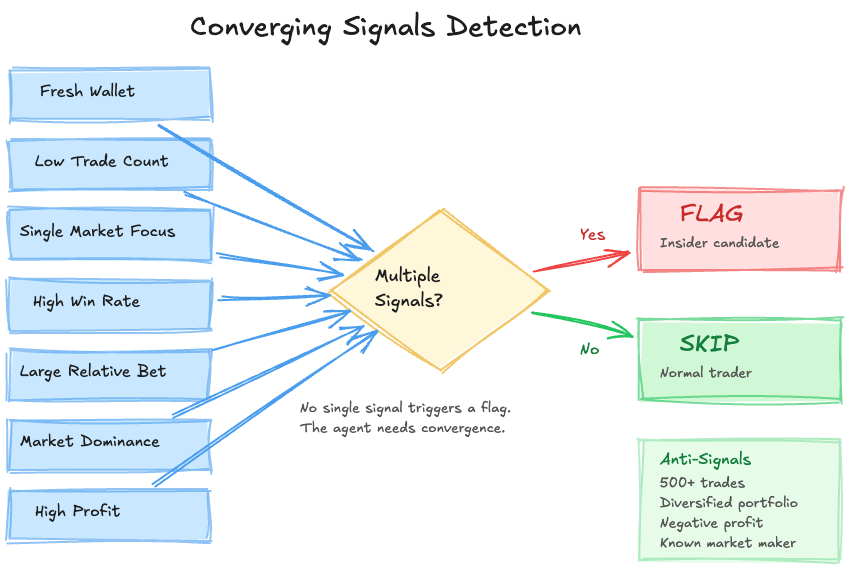
The system prompt also includes explicit anti-false-positive instructions: "Quality over quantity. It's better to flag 0 accounts than to flag false positives." Don't flag whales. Don't flag market makers. Don't flag diversified traders. Don't flag accounts that are losing money.
Production Optimizations
Running an AI agent in a loop gets expensive fast. Several optimizations made this viable for 24/7 operation:
- Sliding window context: Only the last 7 messages stay in the conversation. A
summarizeState()function prepends a compressed summary of all findings so far. - Compressed tool responses: Shortened field names (
addr,amt,side,tsinstead of full names) cut ~60% of tokens per tool call. - In-memory caching: Market context (1-hour TTL) and account profiles (24-hour TTL) prevent redundant API calls within a session.
- Early termination: If after 3+ iterations with zero flags and the agent's output contains phrases like "no suspicious" or "appears normal," the loop breaks. No point burning tokens on clean markets.
- Incremental checkpoints: Each run accepts a map of
marketId → lastAnalyzedTimestampto skip already-analyzed data across runs.
What Went Wrong
Building a detection system in two weeks means you ship bugs. Here are the ones that taught me the most.
The timezone bug that took two days. The agent started flagging "impossible" trades, bets placed after a market had already resolved. Future trades. I thought the model was hallucinating. I tore through the data pipeline, the API responses, the cron job scheduling. Nothing made sense. Two days of staring at timestamps before I realized: Australia and New Zealand are sometimes two calendar days ahead of the US. Polymarket's API returns timezone-naive timestamps. A trade placed at 2 AM on January 5th in Auckland is still January 3rd in New York. The fix was trivial: normalize everything to UTC. The debugging was not.
The false positive flood. Early versions of the agent flagged everything. Anyone with a high win rate. Anyone with a large position. Anyone with a new account. The suspects page was useless. Dozens of flags per run, almost all noise. The breakthrough came from studying what real insider accounts actually look like versus normal traders. Insiders use fresh wallets. They make their bet and disappear. Someone with 500+ trades across dozens of markets isn't an insider. They're a trader. Once I encoded that insight into the agent's methodology, teaching it to heavily weight trade count as the strongest anti-insider signal, false positives dropped dramatically. It sounds obvious in retrospect. It wasn't.
The data integrity problem. Polymarket's Data API occasionally returns incomplete data: accounts showing 500 trades but 0 days old, or holder distributions that don't add up. Early on, the agent was treating this bad data as real evidence, generating high-confidence flags on phantom accounts. The fix: cross-reference everything with The Graph subgraph for on-chain ground truth, and build sanity checks into the tools that estimate account age from trade count when the numbers don't make sense.
The Stack in Practice
Convex handles the database, cron jobs, and real-time sync across five tables: markets, accounts, alerts, agent runs, and an activity feed. The key advantage is real-time subscriptions. When the agent flags a new suspect, the frontend updates instantly via useQuery() hooks. No WebSocket boilerplate, no polling, no cache invalidation logic.
Alert deduplication prevents the same account from generating dozens of alerts across investigation cycles. The alerts.create mutation checks for existing alerts within a 7-day window and only updates if the new severity is higher.
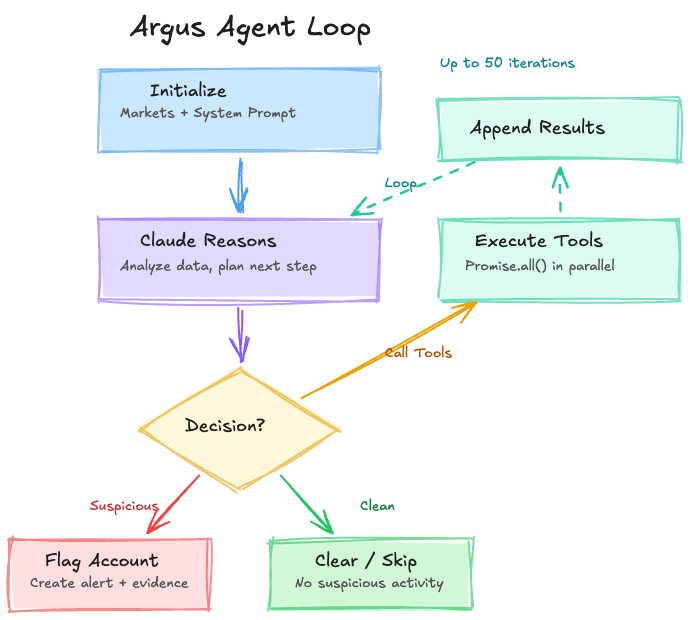
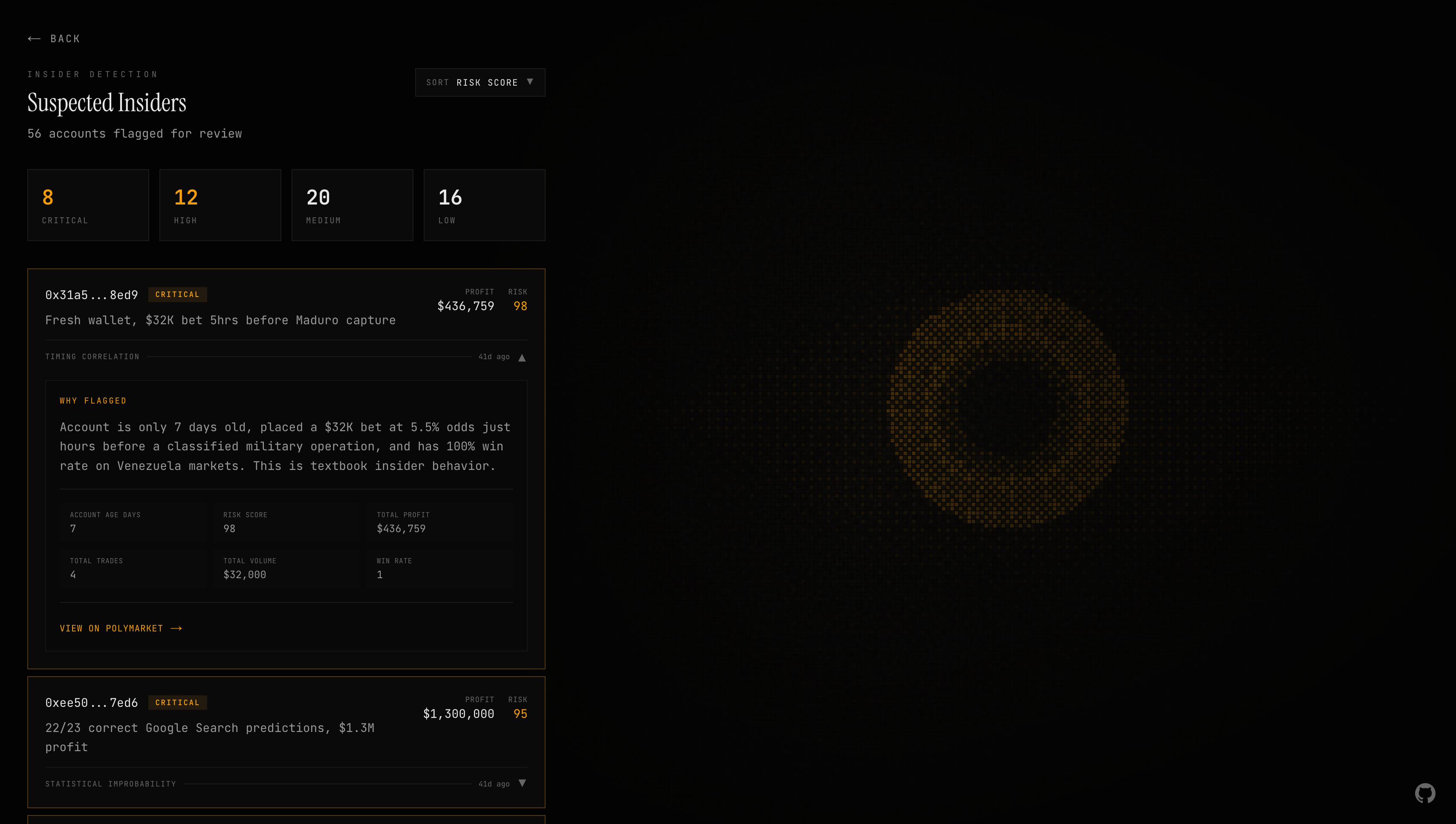
The frontend is built for one job: reviewing flagged accounts and understanding why they were flagged. The suspects page, the bread and butter of the whole system, shows expandable cards with severity badges, risk scores, profit figures, and the agent's full reasoning and evidence. Each card gives a human reviewer everything they need to evaluate whether the flag is real.

The design uses a dark surveillance aesthetic: near-black backgrounds, amber accents, JetBrains Mono for data, Instrument Serif for headings. Animated scanlines and film grain overlays. It looks like it's watching.
What Actually Matters
Looking back at the technical decisions, a few things made the difference between an interesting demo and a system that catches real patterns:
Tools matter more than prompts. I spent a lot of time refining the system prompt. But the biggest improvements came from giving the agent better tools, especially compare_to_market, which lets it evaluate any trader relative to their market context rather than in isolation. A well-designed tool changes what the agent is capable of reasoning about.
Profit as a hard gate. Insiders don't lose money. Building a guardrail into the flagging tool that rejects accounts with less than $100 in profit eliminates an enormous class of false positives at zero computational cost. Simple, but it cut noise dramatically.
Trade count as the strongest anti-signal. This was the biggest lesson. I spent days refining the agent's investigation framework. The single most effective change was teaching it that high trade count is the strongest indicator of a normal account. It encodes a simple truth: people who use prediction markets regularly aren't the ones committing fraud. The ones who show up once, bet big, win, and vanish? Those are the ones to watch.
The Result
Argus won Best Overall at the ColorStack Winter Break Hackathon 2025. 92 participants, 16 projects. It's live at argusai.tech and running autonomously.
What's next:
- Historical insider case training for improved detection calibration
- Expansion to Kalshi and other prediction markets
- Network analysis for coordinated trading rings (multiple wallets, same actor)
- Public API for researchers and journalists
Prediction markets are growing into real information infrastructure. But they need oversight to be trustworthy. Someone needs to watch.
What I'd Do Differently
If I were starting over with more time, three things would change:
Backtesting before shipping. Argus has been validated retroactively against the Maduro and AlphaRaccoon cases, but I don't have precision and recall numbers. I'd build a backtesting framework against a dataset of confirmed insider trades first so I could measure actual detection accuracy, not just "does the reasoning look right to me."
Network analysis from day one. The biggest blind spot is coordinated trading, a single insider splitting their bet across 5 wallets to stay under the radar. Argus evaluates wallets independently right now. Detecting on-chain clusters (wallets funded from the same source, trading in suspiciously similar patterns) is the hardest problem to bolt on after the fact because it requires a fundamentally different data model.
Structured evaluation of agent outputs. Right now, I review the agent's flags manually. That works at current scale but doesn't scale, and it means I'm grading my own work. Building an automated evaluation pipeline that compares agent reasoning against labeled examples would make the system self-improving instead of dependent on me.
Follow Along
I'm building Argus in public.
- Live demo: argusai.tech
- LinkedIn: linkedin.com/in/salimmohamed
- Twitter/X: @salim_a_mohamed